
Kafka - 기초 -
고성능 TCP 네트워크 프로토콜을 통해 통신하는 서버와 클라이언트로 구성된 분산시스템으로 분산형 스트리밍 플랫폼
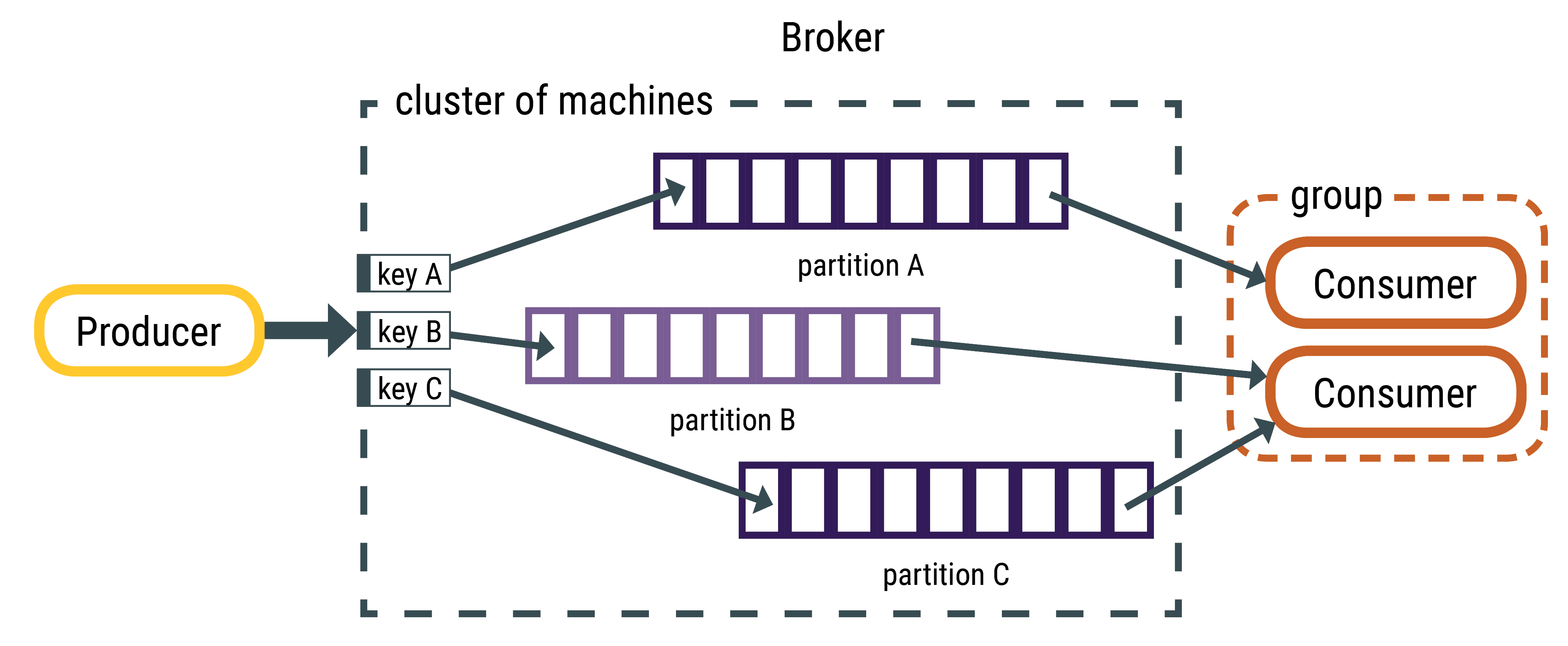
주요 개념
event: [key, value, timestamp, optional metadata headers]로 구성되어 있음
broker: kafka 서버를 의미하며, 한 클러스터에 여러 Kafka 서버를 띄울 수 있음
producer: Kafka에 event를 게시(등록)하는 주체
consumer: event를 구독하는 클라이언트로 해당 event를 읽고 처리함
topic: 파일 시스템의 폴더와 유사하며 event들을 구성하는 곳
partition: 하나의 topic 내에 분산 저장되는 곳으로 여러 partition이 존재 할 수 있으며, 하나의 partition내에서는 Queue 구조로 처리하여 순서를 보장해주지만, partition끼리는 순서를 보장해주지 않음
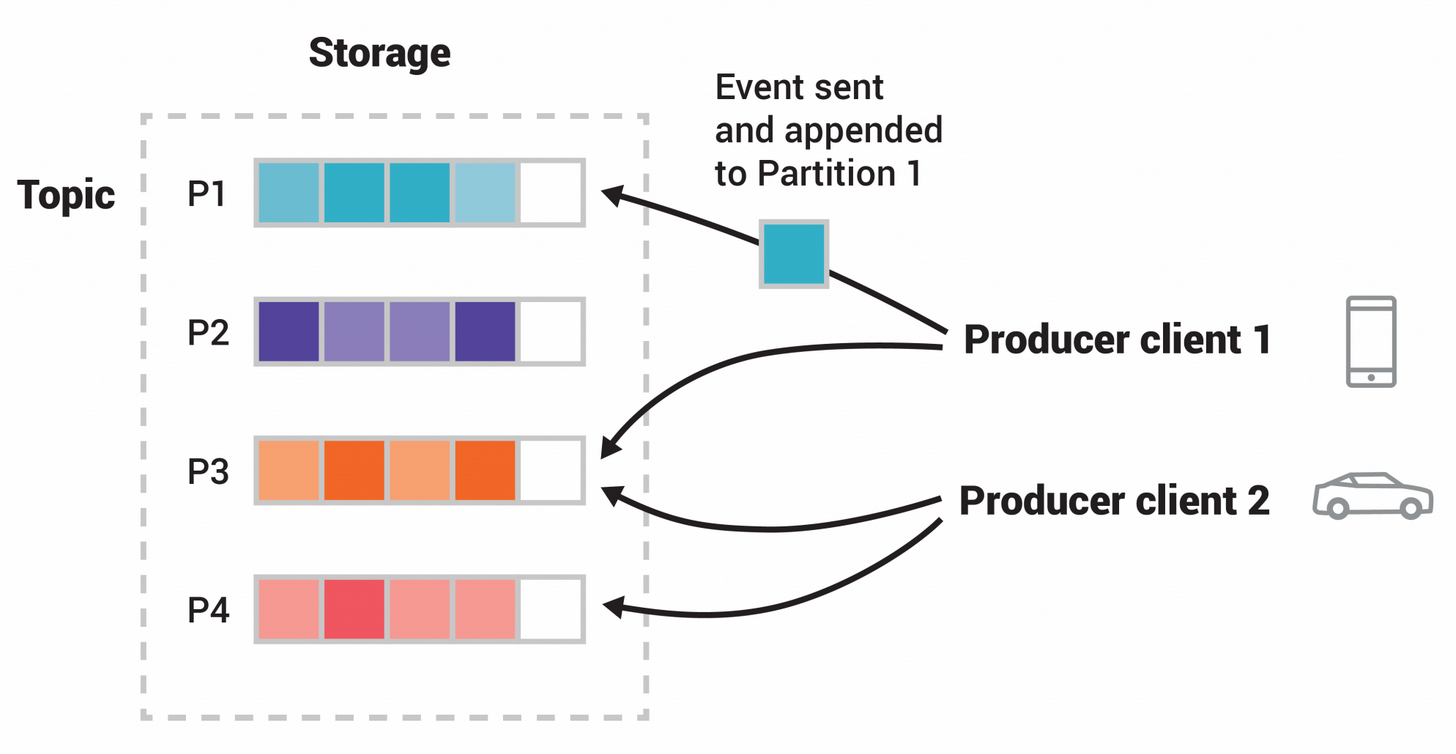
Producer
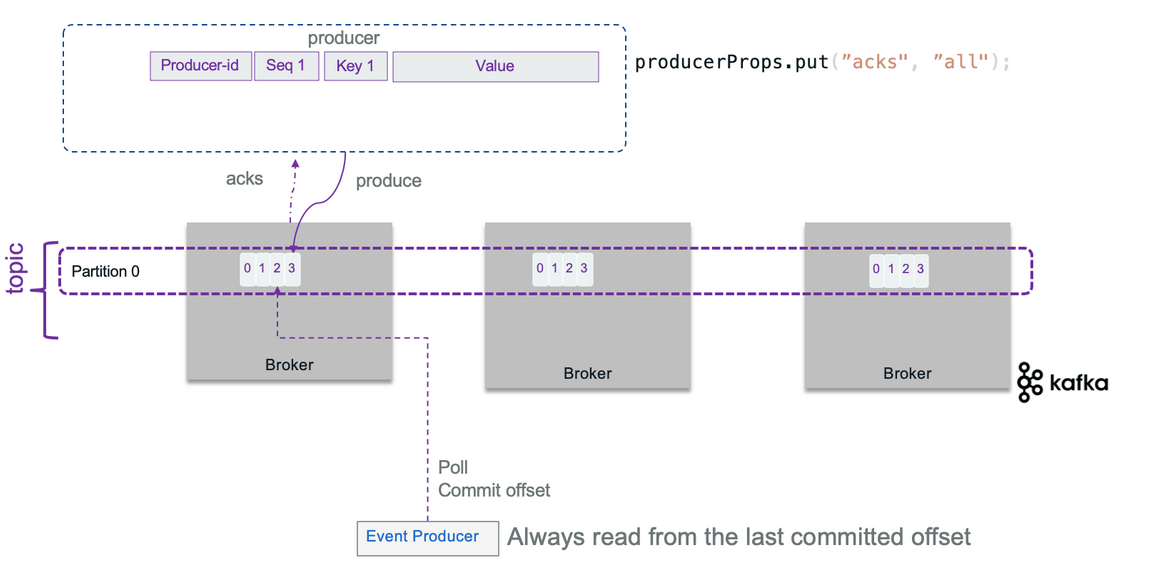
- 정해진 토픽으로 이벤트를 비동기로 게시한다.
- 브로커가 Callback을 해준다.
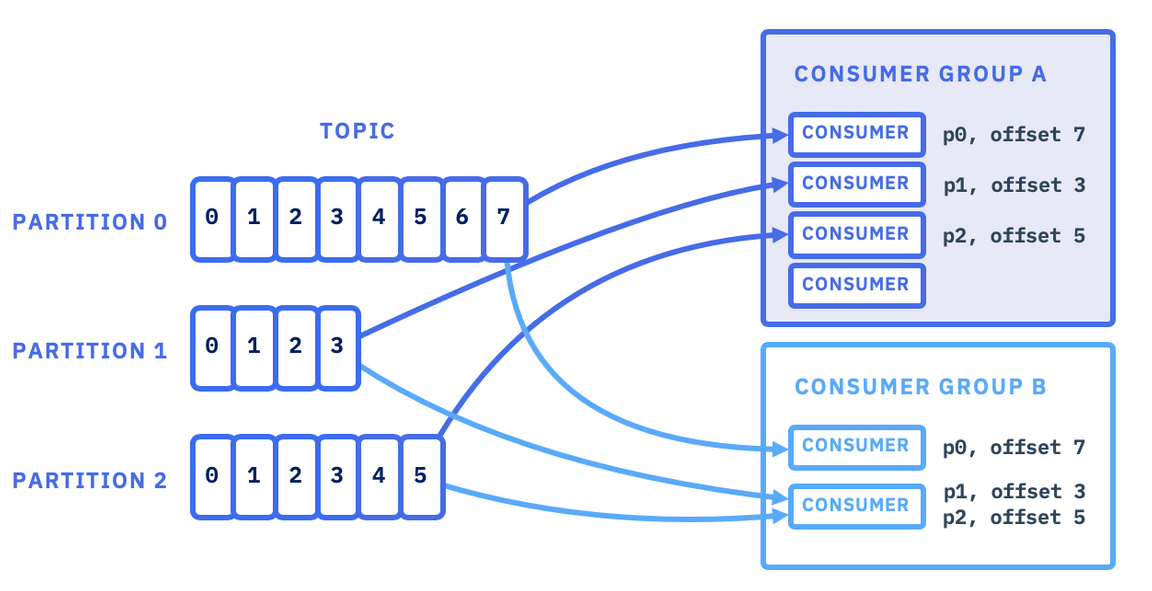
Consumer
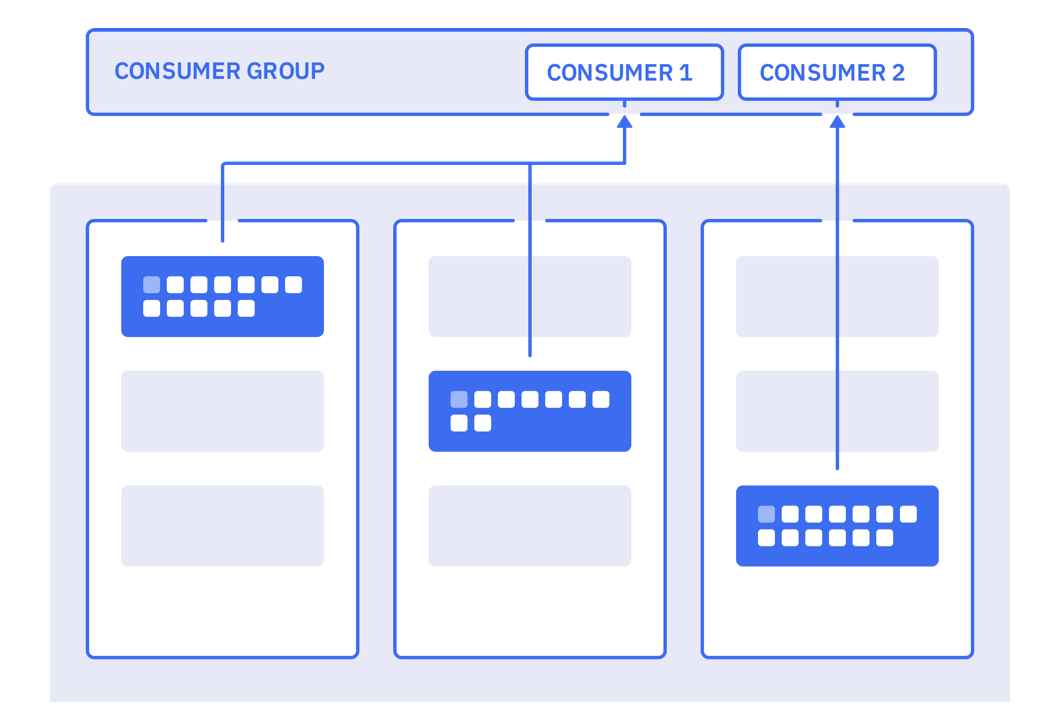
- 세부적으로 Consumer Group과 Consumer Instance로 나뉜다.
- Consumer Group은 각 Consumer Instance의 그룹들을 의미하며 각 Consumer Instance가 처리한 정보(Offset)을 통해 관리한다.
- Consumer Instance는 실질적으로 이벤트를 소비하는 주체이다.
- Consumer Group은 하나의 토픽에 접근 가능하다.
- Consumer Instance는 토픽 내 소비해야할 파티션의 Offset을 Consumer Group에게 공유하며 소비한다.
- Consumer Instance가 일련의 토픽을 구독하며(pull) 할당된 파티션에서 지속적으로 수신한다. 일정 기간동안 heartbeat을 보내지 않으면 죽은 것으로 간주되어 할당된 파티션이 재 할당 된다.
Topic
- 각 이벤트(레코드)는 [key, value, timestamp, optional metadata headers]로 구성되어 있다.
- Producer는 이벤트를 토픽에 게시하며 Consumer는 특정 토픽을 Pull 한다(Polling).
- Producer가 파티션을 지정하지 않고 토픽에 게시하면 key의 해시를 통해 파티션이 선택된다.
- Producer가 timestamp를 지정하지 않으면 현재 시간으로 처리한다.
Partition
- 이벤트 처리를 병렬화하기 위해 사용된다.
- 파티션은 변경 불가능한 시퀀스 큐이며, 시간 순서를 보장한다.
- 한 브로커 당 2000개의 파티션을 지닐 수 있다.
- 각 이벤트(레코드) 마다 고유한 시퀀스 ID(
Offset)가 존재한다. - 기본적으로 이벤트들은 디스크에 저장되며 지정된 크기를 초과할 경우 이전 이벤트들을 삭제한다.
Replication
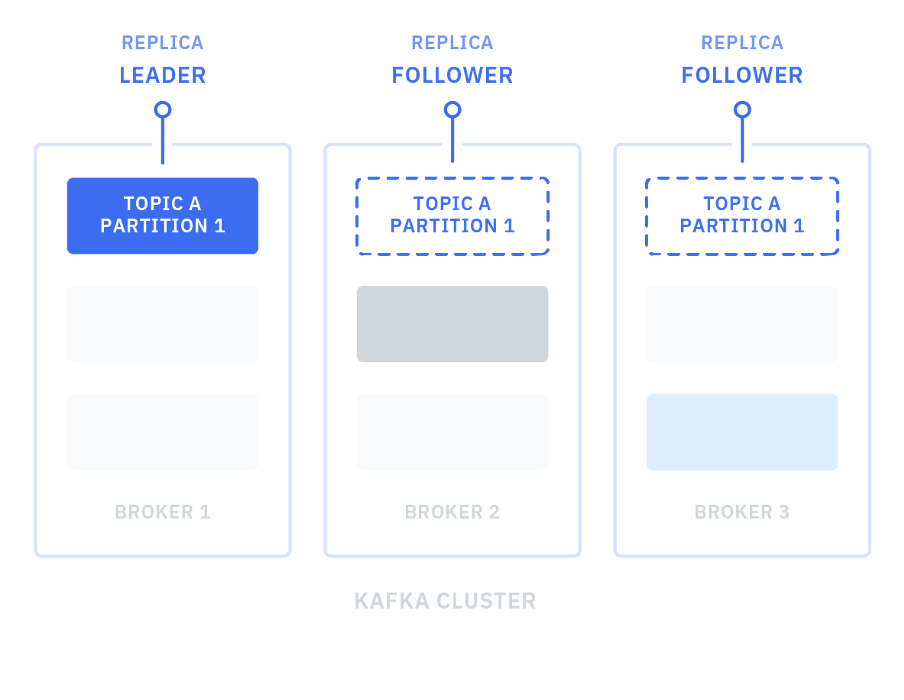
- 각 파티션들은 여러 서버에 복제될 수 있다.
- 고 가용성을 보장하기 위해서는 최소 3이상의 값을 설정 되어야 한다.
- 파티션에는 하나의 리더와 나머지 팔로워로 이뤄져 있다.
- 리더는 해당 파티션에 대한 모든 읽기 & 쓰기 요청을 관리하며, 팔로워는 리더의 컨텐츠를 복제한다.
참고자료
https://kafka.apache.org/intro
https://www.popit.kr/kafka-consumer-group/
https://ibm-cloud-architecture.github.io/refarch-eda/technology/kafka-overview/
Leave a comment